Few would disagree with the tasks and approach to building IT infrastructure and services. You assess the problem and architect a design. Often a proof-of-concept phase is employed whereby confirmation of the platform and capabilities are verified. Piloting the new infrastructure is a common step as validation is necessary to warranty the new architecture will scale and meet the need. As you move into production, a proactive monitoring process is put into place. Last but certainly not least, savvy IT pros will prepare 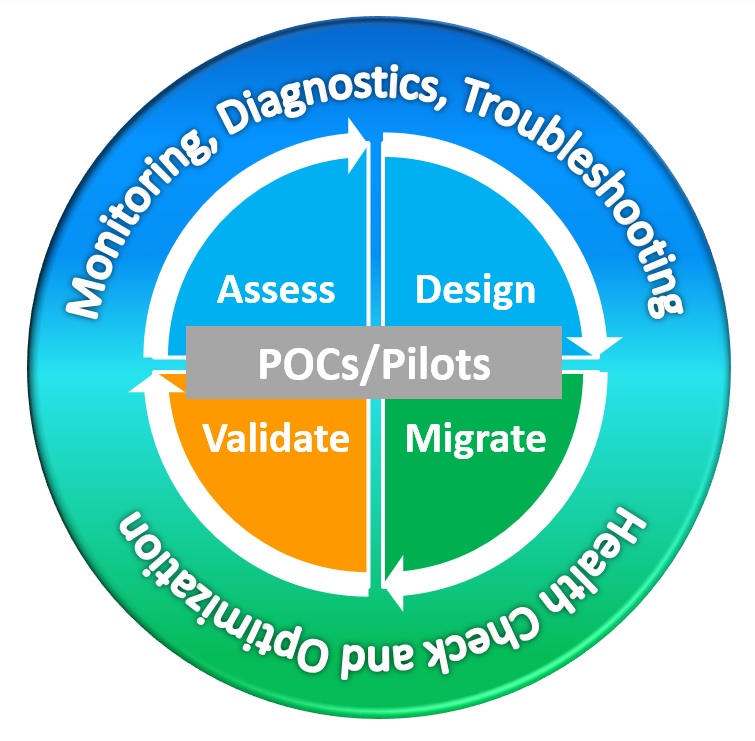 for the inevitable—when something unexpected crops up—and ensure they have the visibility to triage, diagnose and understand where they must focus attention to get back on the right path.
for the inevitable—when something unexpected crops up—and ensure they have the visibility to triage, diagnose and understand where they must focus attention to get back on the right path.
As I often note, I have the great pleasure of being able to speak with many IT practitioners in my job. I have yet to find a single organization that does not subscribe to the above tasks. Not every tasks for every project, but the goals and approach are universal. Interestingly, these tasks are almost always focussed on the IT infrastructure; the servers, storage, networking and other components that comprise the platform. Metrics are defined and measured in such a way to provide details such as CPU capacity, maximum RAM consumed, average and peak IOPs, etc. These are all good measures, but ones that focus exclusively on the hardware and supporting platform.
Related, these tasks are presented and executed as separate and discrete functions. They are approached in a defined order, but the steps are treated as distinct silos. In some organizations there is little continuity of team, measure or definition of success. Each step stands on its own, is defined by its own measure of success and overall forward progress of the project is defined not by a universal indicator, but by a series disconnected tasks.
Turning Silos on their Head
Don’t misunderstand. I often employ and preach the benefit of these steps in customer conversations. I absolutely promote the tasks as critically important—especially in the practice of end user workspaces. Any organization that does not define a methodology comprised of most (if not all) of the steps mentioned above is not doing their part to minimize project risk.
My point is more about changing your point-of-view. In the case of end user workloads it’s the user perception that is most important; not the infrastructure or platform-centric view. I spoke a bit about this about a year ago in The Yin and Yang of Virtual Desktop Workloads. In fact, if you string the aforementioned tasks of assess, design, migrate, validate, monitor, diagnose, troubleshoot, optimize, etc. end-to-end, you’ll note these are all phases in a user-centric lifecycle. Each and every step in the process is ultimately a step that provides some benefit to the user and the user experience.
This is a core differentiator for Stratusphere UX. While we support and are often used for the silos discussed, it is Stratusphere’s capability to examine and support the entire lifecycle that sets the solution apart. Yes, the individual tasks may be critically important to 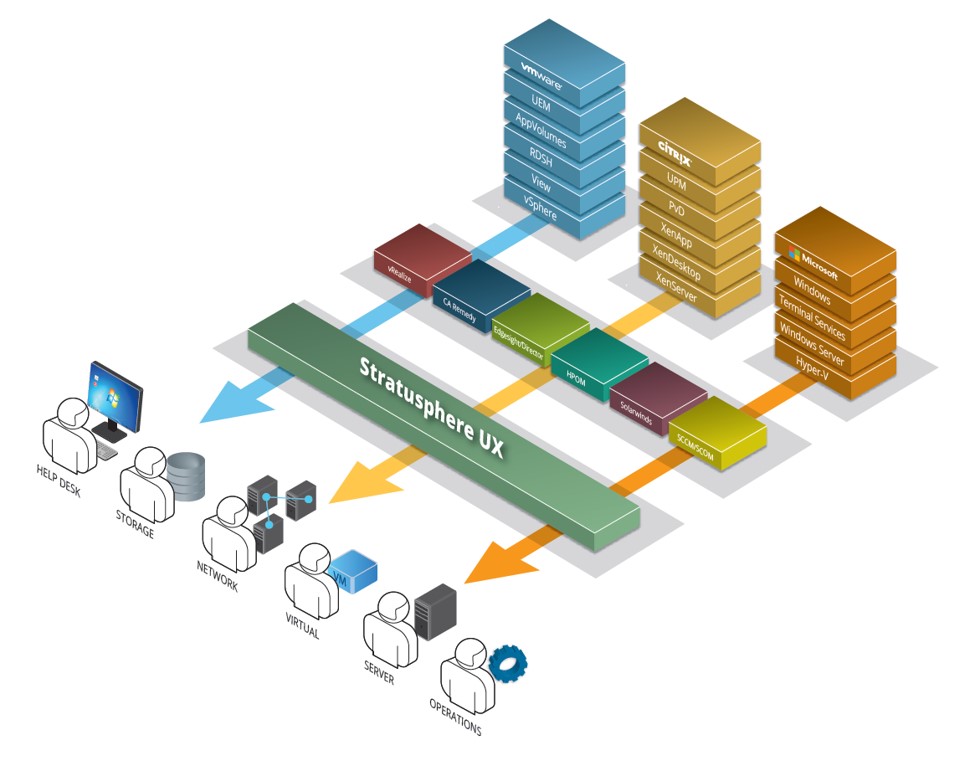 different IT groups and functions throughout the user lifecycle. But it it the user experience that must be measured and maintained if you are to minimize disruption, dazzle users and proactively define success in the delivery of technologies such as VDI, application publishing, terminal services, and other virtualized user workspace delivery.
different IT groups and functions throughout the user lifecycle. But it it the user experience that must be measured and maintained if you are to minimize disruption, dazzle users and proactively define success in the delivery of technologies such as VDI, application publishing, terminal services, and other virtualized user workspace delivery.
Windows-Based Workload Cornucopia
Moreover, it is common for organizations to employ more than one Windows delivery approach to its user-base. Perhaps a user has a traditional operating system and laptop while on the road, Citrix XenDesktop or VMware View when in the corporate office and RDSH or XenApp-delivered applications thrown in for good measure. The reality and end result is one part business logic and one part historic implementation, which presents a cornucopia of Windows delivery approaches for the majority of organizations. Then why measure and define success for each separately? The users don’t see it that way.
From the user point-of-view, the desktop is broken. Logins are slow. The application failed to load. Do they immediately know it is VDI, or RDSH, or a physical laptop? They may appreciate the problem happens every Thursday, when working on XenDesktop, but they rarely connect all the dots. So why manage and define key performance indicators that tie exclusively back to the supporting infrastructure?
It’s the User That Must be Prioritized
Stratusphere UX presents a composite metric that defines the user experience. I’ve discussed this before, but what’s important to note is this measure of user experience is persistent. It follows the user, regardless of platform or architecture. It is a metric that is trended over time, can be examined at a very high level, and can be drilled into to determine commonalities that may tie back to a specific Windows delivery approaches.
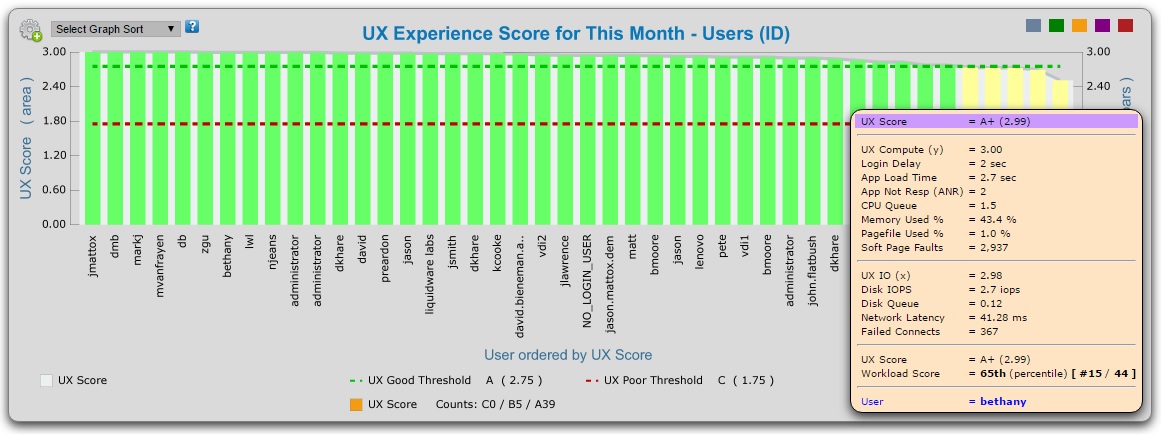
Infrastructure will come and go. Platforms change, and best practices for workspace deployments will evolve. What remains persistent are users. Meeting expectations and performance requirements—ultimately the user experience—is the only metric that matters. Keep an eye on your infrastructure, but keep a closer eye on user experience as it should define your success in delivering end user workspaces.






Leave A Comment
You must be logged in to post a comment.